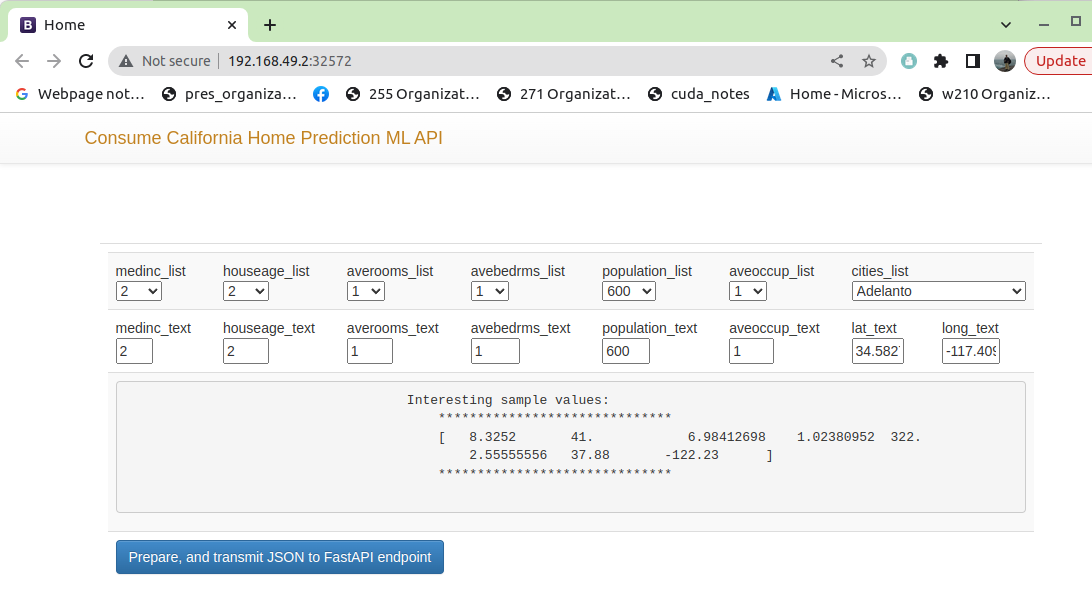
Running End-to-End (run.sh Script)
Once the dependencies are installed, we’re able to run the system end to end.
This is done through the run.sh script which orchestrates requirements harvesting, testing, image building, delpoyment management and waiting for web applications to be up.
If the repo has already been cloned, move into the download directory and use the following command:
. run.sh
If the repo has not yet been cloned, run the following command to pull down the repo and run the system:
git clone https://github.com/Don-Irwin/fastapi_ml_k8_k6_gh_actions && cd ./fastapi_ml_k8_k6_gh_actions && . run.sh
Accessing the Three UIs Exposed:
If the system is able to run end-to-end, we should see this message.
The message below is misleading and yet not, in that it is referencing the ip addresses and ports within minikube (which indeed will render on your local box) – however, if you wish to expose these ports your network or the internet these ip addresses are not useful. Rather the ports below (which may be configured within the deployment YML and port forwarding set ups) are better.
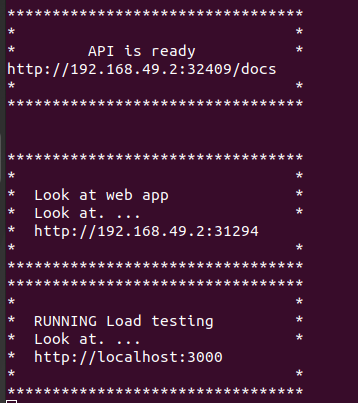
Upon seeing this message we should be able to open:
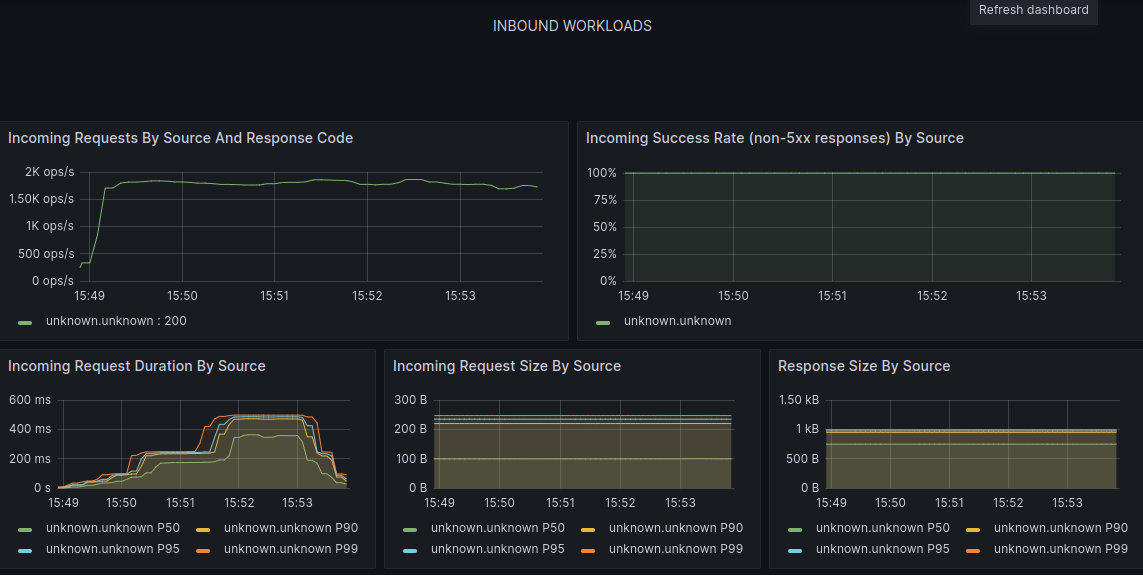
- Grafana – in order to see the progress of the load testing (which will be running):
Ctrl + Click – to open in new tab.
Grafana http://localhost:3000
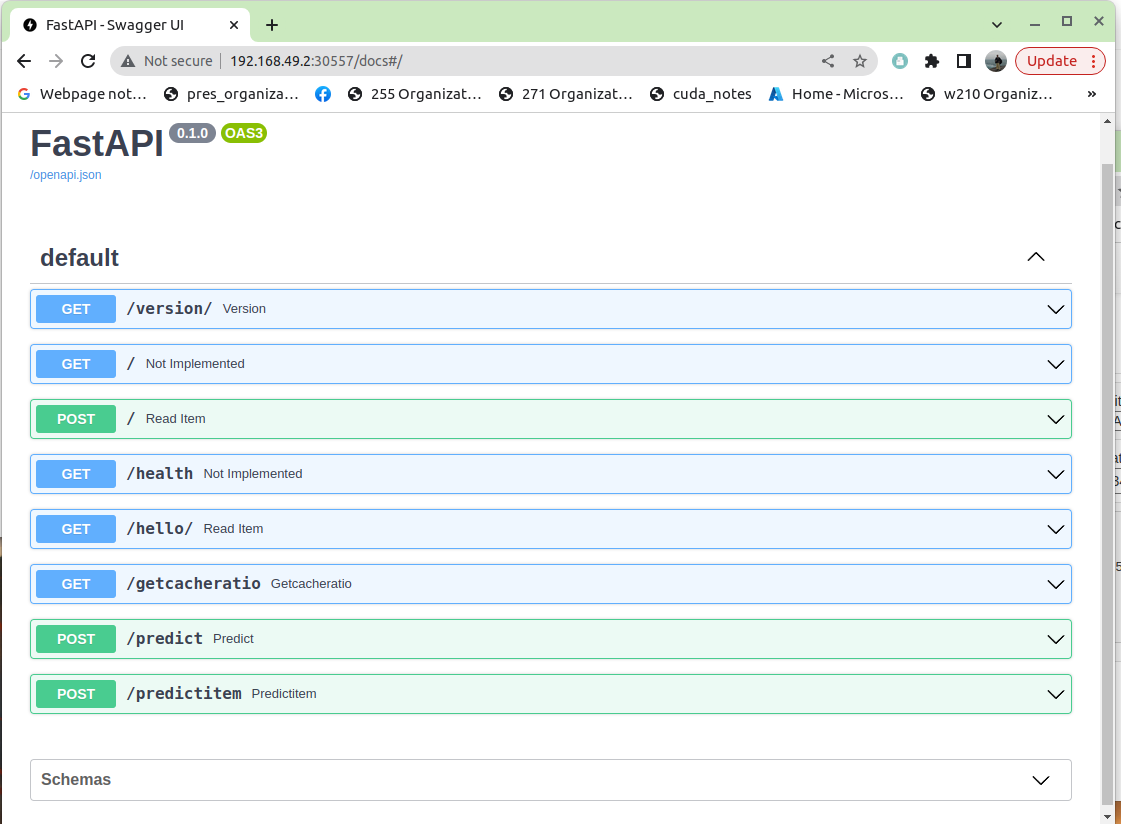
- The FASTAP swagger interface:
Ctrl + Click – to open in new tab.
FastAPI Interface http://localhost:8000/docs
- The Flask Web Application:
Ctrl + Click – to open in new tab.
Flask Web Application http://localhost:5000